/image%2F0200700%2F201211%2Fob_55dbc80e607f6f565a3408599e13665d_image.png "Adèle Désoyer, Anastasia Fomina, Dalila Rome")
Phrase 2 Le Trameur
Publié le 29 Janvier 2013
On peut pousser encore plus l'analyses de nos données finales grâce à la textométrie, qui nous permet de compter des éléments textuels contenus dans un de nos fichier. Pour ce faire, on vas utiliser un logiciel appelé Trameur. Ce logiciel va tout d'abord considérer notre fichier texte comme un contenant qui regroupe des unités élémentaires, afin de relever des séquences de caractères organisées. On chargera dans le Trameur les fichiers CONTEXTES-GLOBAUX et DUMPS-GLOBAUX de nos trois langues.
Première chose à faire, définir la langue d'encodage des fichiers à charger, dans l'onglet paramètre....mais un premier problème de pose. Notre fichier français en UTF-8 ne chargent pas, et le problème viendrait du format d'encodage. On retente en notant que l'encodage du fichier entrant est de l'ISO 8859-1, et le trameur accepte enfin notre fichier français. Cependant, l'encodage n'étant pas le bon, on retrouve les éternels problèmes d'encodage des caractères accentués.... Pour les fichiers contexte russe et italien, on n'a pas eu ce problème, et on a paramétré l'encodage en UTF-8?
Le trameur lancé, on obtient tout de même le fichier CONTEXTE-GLOBAL du français, et dans l'onglet Forme-Lemme, on a apparement le rendu souhaité...puis un seconde problème. Notre mots en français est un mot composé. En entrant le motif du mot recherché, soit (sans-papier?), on obtient :
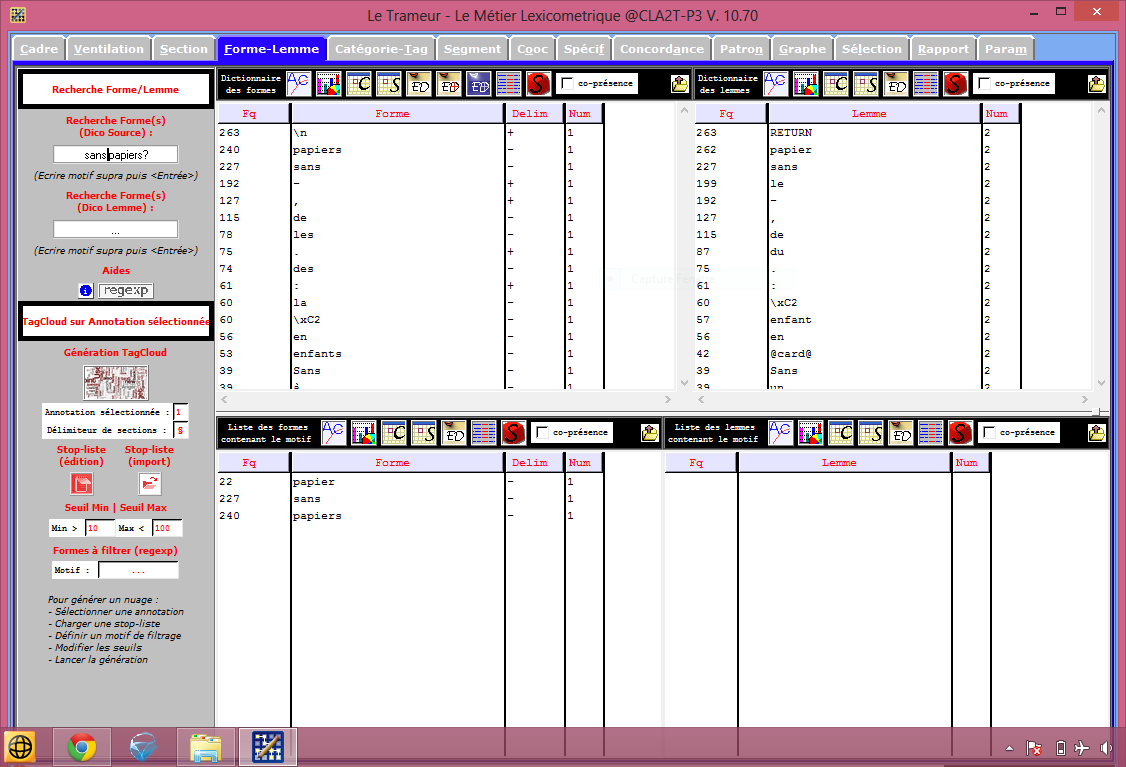
On retourne dans l'onglet paramètre, et on retire de la case délimiteur le tiret qui fait partir des délimiteurs paramétrés par défaut.
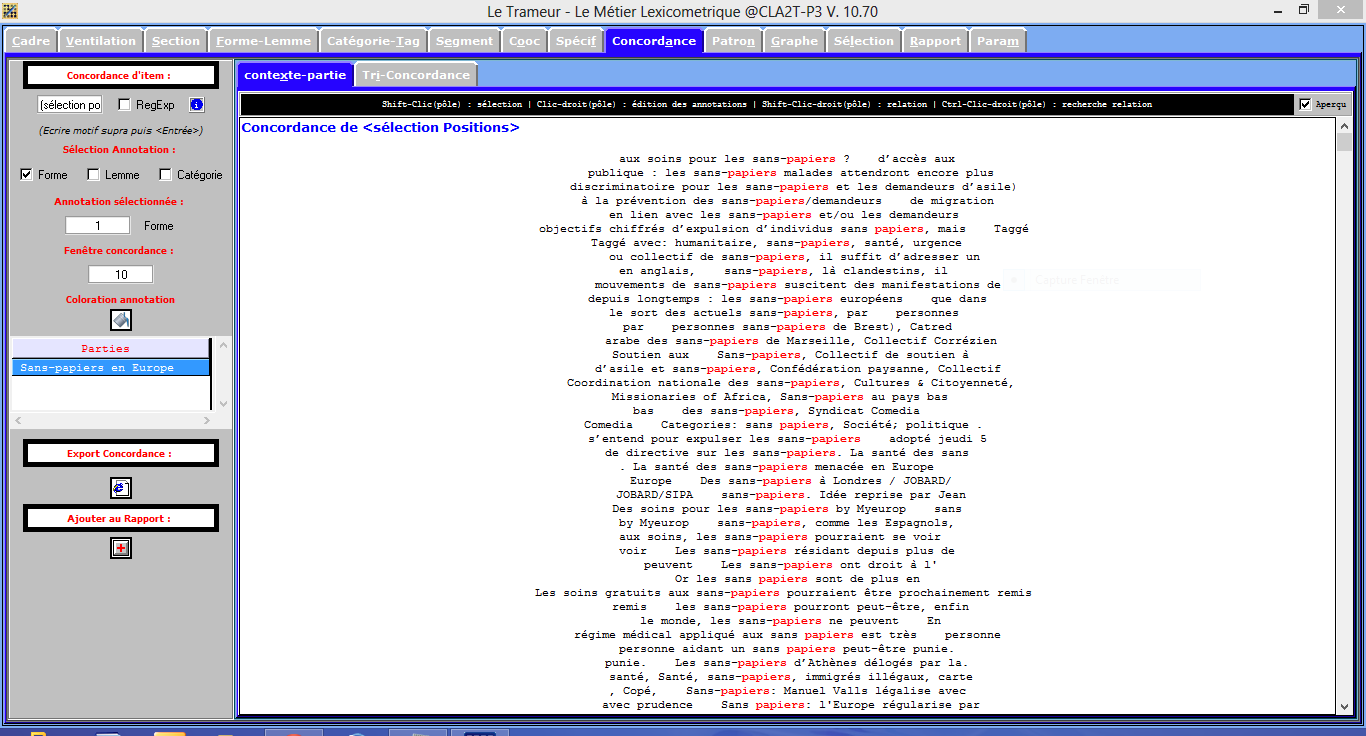
On obtient alors.

On se souvient des fameux délimiteurs à mettre en fin de ligne. Le délimiteur est un caractère choisi (dans notre cas c'est un #) que l'on va mettre à la fin de chaque ligne de texte du fichier. Il est important de "nettoyer" le texte avant, en vérifiant qu'il n'y a pas d'autre "#" dans le texte qui pourraient être confondu avec nos délimiteurs. Le délimiteur a pour fonction de définir précisément des séquences de caractères significatives.
On a choisi de prendre le symbole #. On fait donc quelques modifications dans l'un des fichiers que l'on va analyser. On crée une copie du fichier global des contextes de l'italien pour y modifier le contenus textuel en y ajoutant notre #. Cette copie nous sera utiles pour extraire les co-occurents dans le fichier.
Pour l'italien, où l'on prend comme motif clandestini, tout semble fonctionner.
On retourne donc dans les paramètres, et dans la case 'délimiteur' on inscrit #. Puis on charge le fichier CONTEXTE-GLOBAL de l'italien avec délimiteurs. On peut enfin lancer le trameur.
On obtient avec le motif "clandestini" :


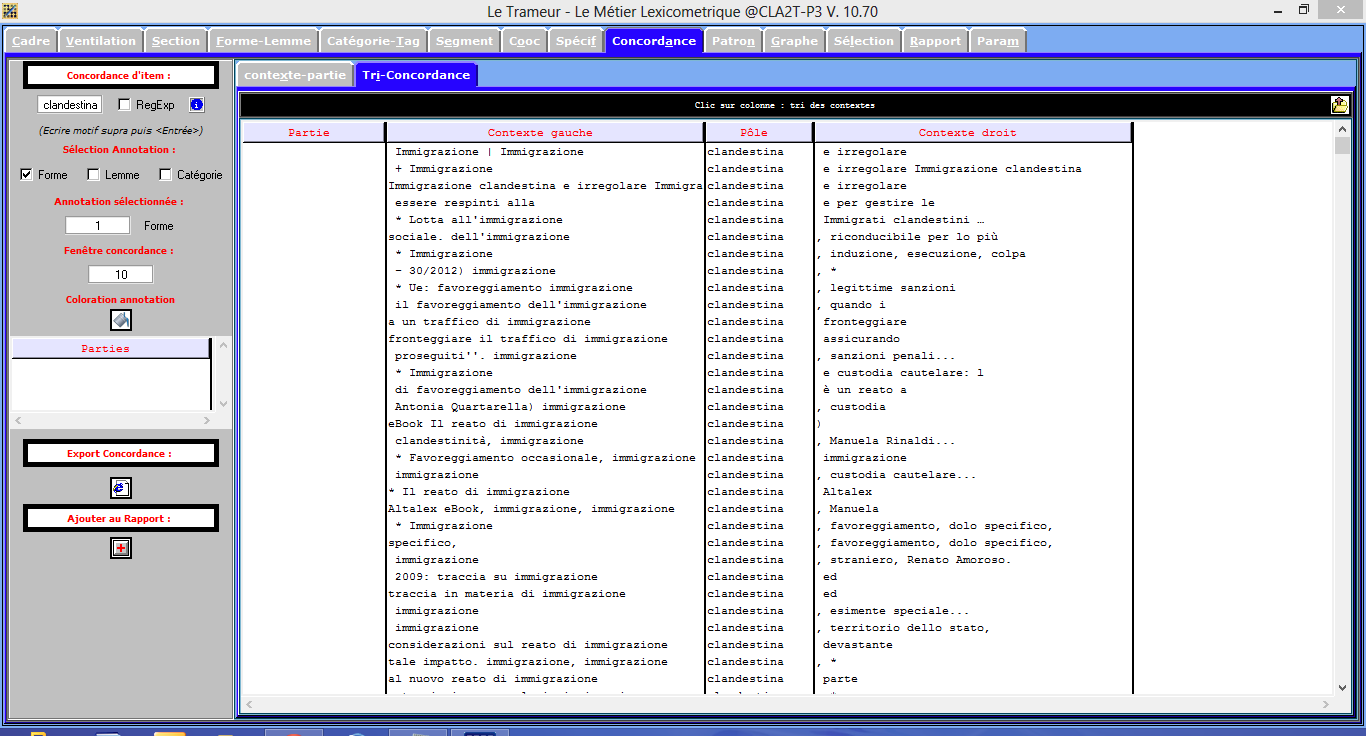
Onglets Forme-Lemme et Concordance
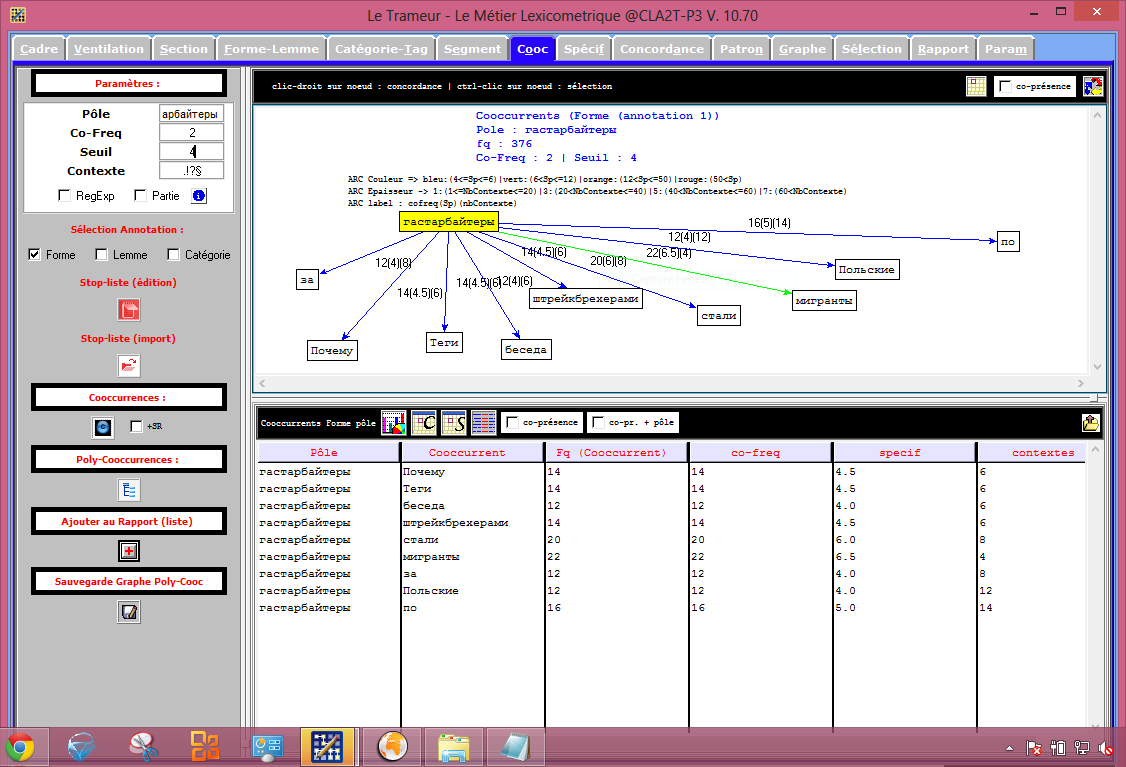
Et même un arbre ! (L'arbre à été généré à partir du fichier qui ne contenait pas le délimiteur # en fin de ligne.) Le fichier étant assez important, l'arbre est assez dense avec les paramêtre par défaut, ce qui peut rendre sa lecture assez compliquée.

On décide donc de modifier la valeur de la case seuil. nous ne gardont que les co-occurent les plus pertinents. On obtient alors l'arbre en italien suivant:
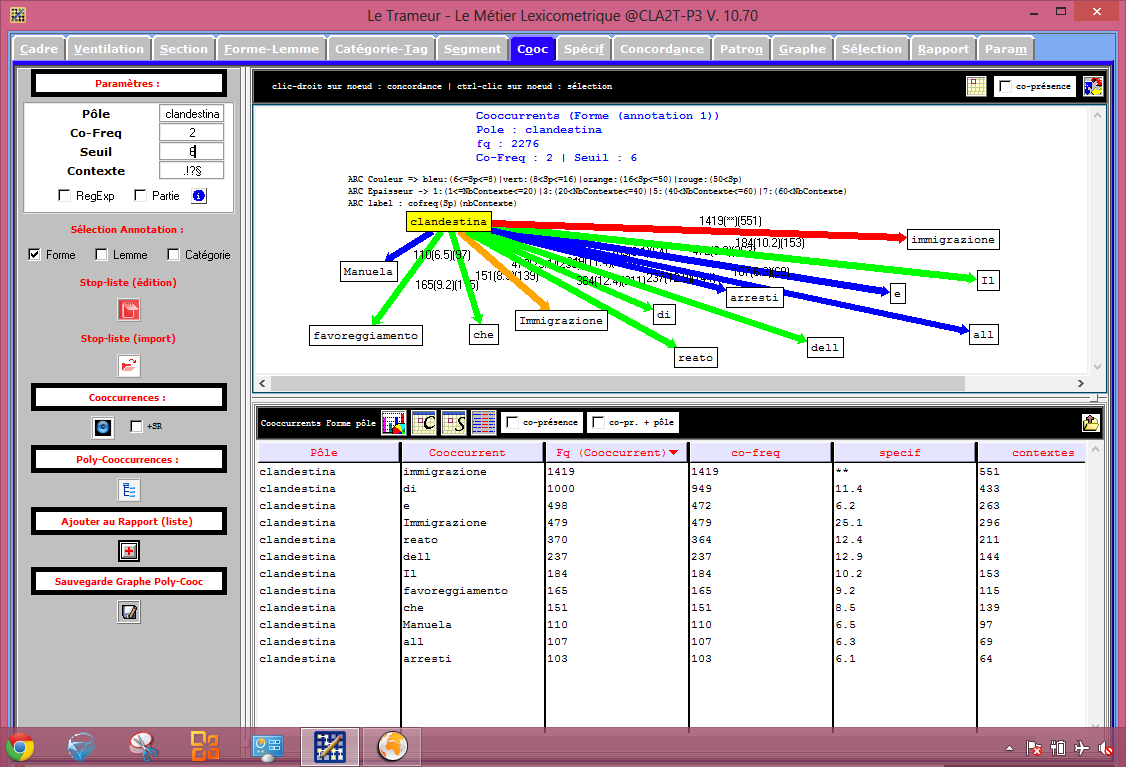
et pour les fichiers en français et en russe